在 Fedora 上入门 Jupyter 与数据科学
本文翻译自 Avi Alkalay 的文章 Jupyter and data science in Fedora。
在过去,君主和领袖会依赖先知和巫师来预测未来——或者借助其神秘力量来探测潜在信息。现如今,我们则更追求能对所有的事物进行量化。于是我们便有了数据科学来完成这些工作。
数据科学家使用统计学科之外的统计模型、数学技术和高级算法,针对数据库中存在的数据,进行查找、推断、预测潜在的隐性数据。有时,这些数据就关乎未来。正因如此,我们才会去做很多预测性分析和规范性分析。
数据科学家会致力于研究类似以下这些问题:
- 哪些学生比较有翘课倾向?具体到个人,其背后的原因有哪些?
- 哪套房子的价格超出或低于合理的价位?对于某一套房,其合理的价格是多少?
- 我的客户会自我归类到哪些隐性群体?
- 某个早产儿会在未来遇到哪些问题?
- 我明天上午 11:43 会在呼叫中心接到多少电话?
- 我的银行该不该贷款给这个客户?
要知道以上这些问题的答案并不会躺在哪个数据库里等人去查。这些数据都是需要计算的,不然根本就不会存在。而这正是数据科学家工作内容的一部分。
在本文中,你可以学到如何将 Fedora 系统打造成为数据科学家的开发及生产系统。大部分基础软件都打好 RPM 包了,不过目前比较高阶的部分只能通过 Python 的 pip 工具安装。
Jupyter——集成开发环境
大部分新潮的数据科学家都用 Python。而他们工作中非常重要的一环就是 EDA(探索性数据分析)。EDA 是一个手动和交互式过程,可以检索数据,探索其特性,搜索相关性,并通过绘制图形来进行可视化,进而理解数据的全貌和原型预测模型。
Jupyter 是一款可以完美适用于这些任务的 web 应用。Jupyter 可以搭配 Notebooks(笔记本)、文档来使用,其中可以整合富文本,包括渲染精美的数学公式(得益于 mathjax 的加持)、代码块、代码输出,甚至还包括输出的图像等。
Notebook 文件的扩展名是 .ipynb,意思是「交互式 Python 笔记本」(Interactive Python Notebook)。
设置和运行 Jupyter
首先,使用 sudo 安装 Jupyter 所需的基础软件包。
$ sudo dnf install python3-notebook mathjax sscg
另外你可能还需要安装一些数据科学家通常会用到的 Python 附加模块及可选模块:
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
可以设置一个密码,这样登录 Notebook 的 web 界面时就不必拖着那一长串 token 了。打开终端,执行以下命令:
$ mkdir -p $HOME/.jupyter
$ jupyter notebook password
然后设置你的密码。该命令会创建一个 $HOME/.jupyter/jupyter_notebook_config.json 文件,你的密码经过加密后便会存在其中。
接下来,为 Jupyter web 服务器生成自签 HTTPS 证书:
$ cd $HOME/.jupyter; sscg
通过编辑你的 $HOME/.jupyter/jupyter_notebook_config.json 文件来完成 Jupyter 的设置。这个文件会长成这个样子:
{
"NotebookApp": {
"password": "sha1:abf58...87b",
"ip": "*",
"allow_origin": "*",
"allow_remote_access": true,
"open_browser": false,
"websocket_compression_options": {},
"certfile": "/home/aviram/.jupyter/service.pem",
"keyfile": "/home/aviram/.jupyter/service-key.pem",
"notebook_dir": "/home/aviram/Notebooks"
}
}
涉及到文件路径时,家目录的路径需要改成你自己的。密码那一串是当你创建密码时自动生成的。pem 相关的那一部分是 sscg 创建的加密相关的文件。
为你的 Notebook 文件创建一个文件夹,与上面配置文件中 notebook_dir 设置项保持一致:
$ mkdir $HOME/Notebooks
现在一切就绪。通过以下命令来运行 Jupyter Notebook:
$ jupyter notebook
或者你也可以在你的 $HOME/.bashrc 文件中加一行,比如设置一个名叫 jn 的命令别名:
alias jn='jupyter notebook'
之后执行命令 jn,然后从浏览器打开 https://localhost:8888 就能看到 Jupyter 的界面了。此时需要敲一遍你在前面设置的密码。接下来你就可以写一些 Python 代码或者标记文本了。大概会长这个样子:
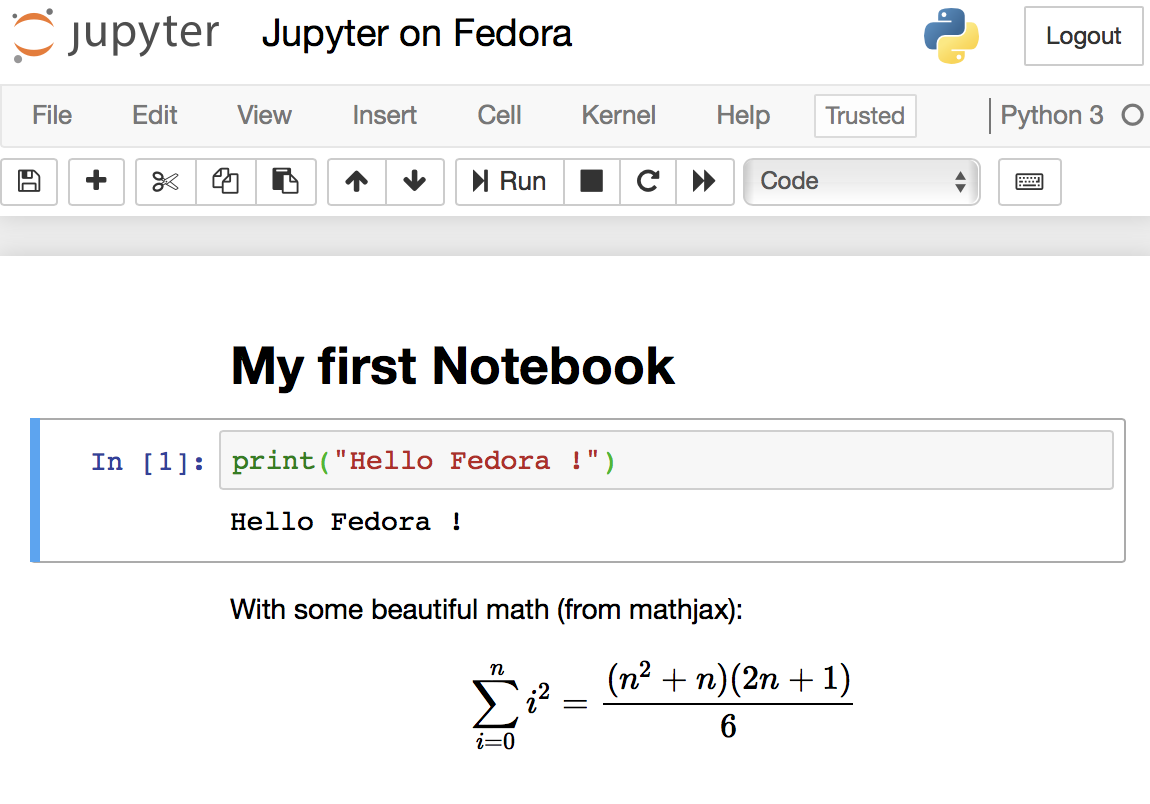
Jupyter 中的一个简单的 Notebook
除了 IPython 环境之外,你还可以通过它来使用 terminado 提供的网页版 Unix 终端。有些朋友会觉得这个功能很实用,不过也有人认为这个不安全。你可以在配置文件中将其禁用掉。
JupyterLab——下一代 Jupyter
JupyterLab 可以看作是新一代的 Jupyter,界面更友好,工作区的可控制性更高。截至本文发布时还没有针对 Fedora 打的 RPM 包,所以你需要使用 pip 来安装:
$ pip3 install jupyterlab --user
$ jupyter serverextension enable --py jupyterlab
然后运行常规的 jupyter notebook 命令或者是前面定义的 jn 这个别名。打开 http://localhost:8888/lab 这个网址就可以访问 JupyterLab 了。
数据科学家用到的工具
在这一部分中,你可以了解一下部分工具以及安装方法。没有特殊说明的话,就意味着这些工具在 Fedora 上已有现成的包,而且由于前面组件的依赖关系,已经安装好了。
Numpy
Numpy 是一款高级的数学相关的库,经过 C 语言的优化,其设计目的是为了处理大型内存数据集。它可以提供高级的多维矩阵支持及相应操作,还包括了诸如 log()、exp()、三角函数等数学函数。
Pandas
在笔者看来,Python 之所以能成为数据科学的热门选择,Pandas 功不可没。Pandas 基于 numpy,它可以让准备和显示数据的工作变得更加轻松。你可以把它想象成一个没有界面的电子表格,但是它可以处理相当大的数据集。Pandas 可以帮我们从 SQL 数据库、CSV(逗号分隔值文件)或者是其他类型的文件中读取数据、操作行或列、筛选数据以及某些情况下使用 matplotlib 进行数据可视化操作等。
Matplotlib
Matplotlib 是一个用于绘制 2D 和 3D 数据的库。它对于图形、标签或者图层中的标记都有非常良好的支持。
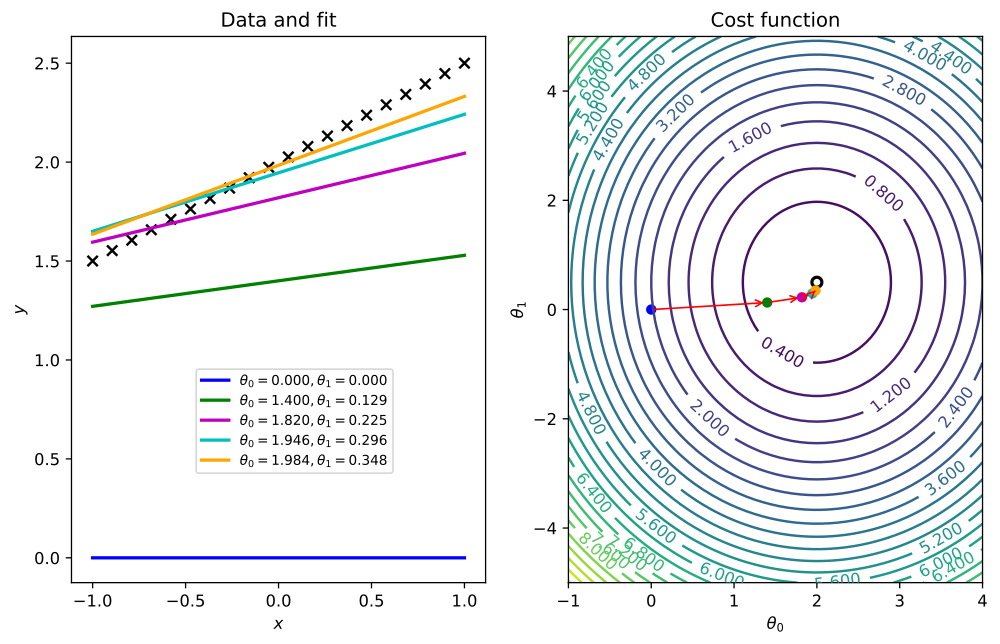
通过梯度下降算法搜索一个成本函数的最优值,用 matplotlib 绘制的一对图形
Seaborn
Seaborn 基于 matplotlib 进行构建,其绘图是经过优化的,可以更好地统计数据。它会自动画出数据的回归线或高斯曲线近似值。
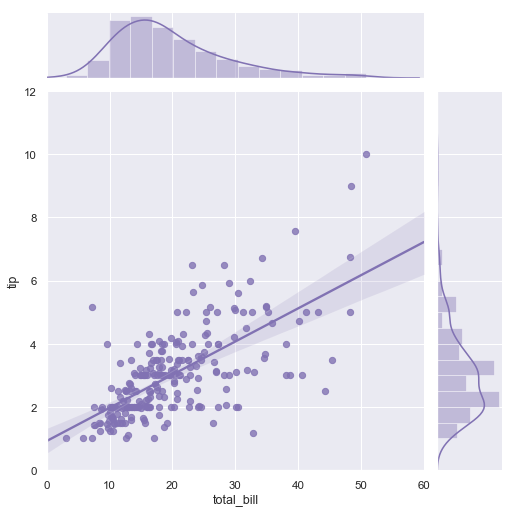
利用 SeaBorn 进行线性回归的可视化
StatsModels
StatsModels 可以为统计和计量经济学数据分析提供算法,如线性和逻辑回归。Statsmodel 同样适用于 ARIMA 等经典时间序列算法系列。
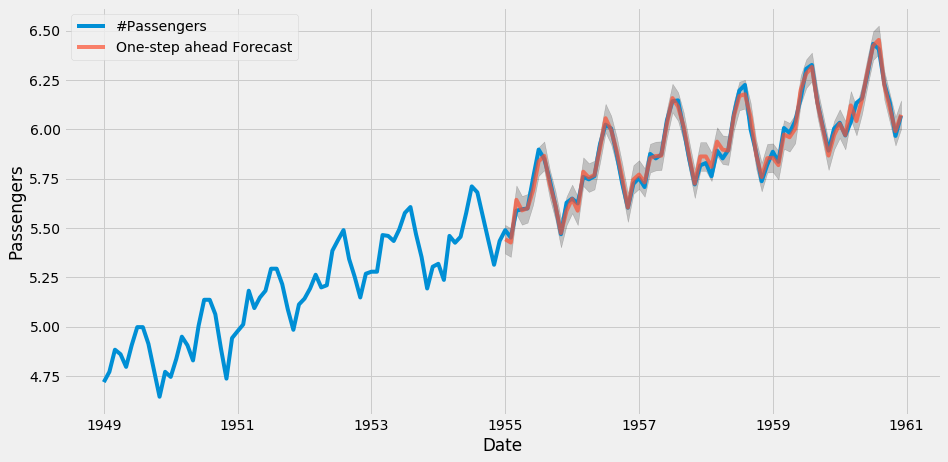
归一化之后的旅客量随时间变化趋势(蓝线)与 ARIMA 预测的旅客量(红线)
Scikit-learn
作为机器学习生态系统的核心部分,scikit 为回归(弹性网、梯度提升、随机森林等)以及分类和聚类(K-means、DBSCAN等)提供了算法。它的一大特性就是 API 设计得非常好。Scikit 有很多类别,可用于高级数据操作、将数据集拆分为训练和测试部分、降维以及数据管道准备等。
XGBoost
XGBoost 是目前使用的最优秀的回归和分类工具。它并不是 scikit-learn 的一部分,但是也遵循了 scikit 的 API。XGBoost 在 Fedora 上并没有现成的 RPM 包,所以要用 pip 来安装。XGBoost 可以通过英伟达 GPU 加速,但是这一功能并不包含在其 pip 包里。你可以通过自行针对 CUDA 编译来实现。安装方法:
$ pip3 install xgboost --user
Imbalanced Learn
imbalanced-learn 可以提供对数据进行欠采样和过采样的方法。这在欺诈检测场景中非常实用,因为与非欺诈数据相比,已知的欺诈数据会非常小。这时,就需要针对已知欺诈数据进行数据扩大,以使其与训练预测工具更相匹配。使用 pip 安装:
$ pip3 install imblearn --user
NLTK
自然语言工具箱,或者叫 NLTK,可以帮我们处理人类语言数据,从而实现构建例如聊天机器人之类的工具。
SHAP
机器学习算法非常擅长预测,但不善于解释他们为什么会得出该预测结果。SHAP 就是为了解决这一问题,方法就是分析训练的模型。
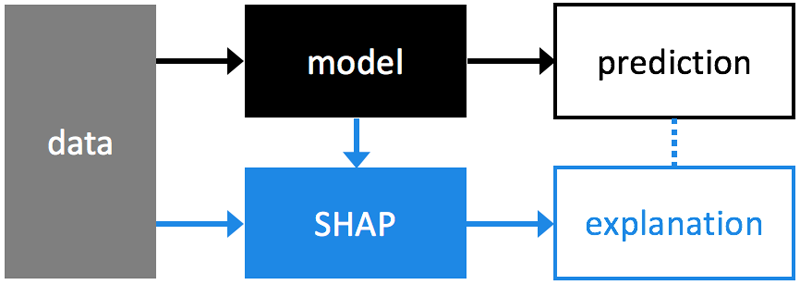
SHAP 在数据分析过程中所处的位置
使用 pip 安装:
$ pip3 install shap --user
Keras
Keras 是一个针对深度学习和神经网络的库。使用 pip 安装:
$ sudo dnf install python3-h5py
$ pip3 install keras --user
TensorFlow
TensorFlow 是一款非常流行的神经网络构建工具。使用 pip 安装:
$ pip3 install tensorflow --user